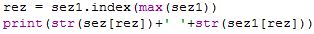

Besedilo naloge
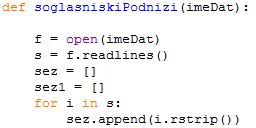
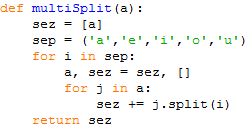
1. Soglasniški podnizi Na standardnem vhodu imamo zapisane besede, vsako v svoji vrstici. V njih nastopajo le male crke angleške abecede, nobene številke ali locila ni. Nobena beseda ni daljša od 100 znakov. Zanima nas beseda, v kateri se nahaja najdaljši strnjeni podniz soglasnikov. Za soglasnike štejemo vse crke, ki niso samoglasniki (a, e, i, o, u). Tule je nekaj primerov besed, poleg vsake besede smo zapisali iskano dolžino, podzaporedje pa zapisali v krepkem tisku:
in 1
pristno 3
toreador 1
strjenka 4
a 0
skrbstvo 7
besedna 2
krt 3
Napiši program, ki bo prebral zaporedje besed s standardnega vhoda in nato izpisal na standardni izhod besedo, ki je vsebovala najdaljši strnjeni podniz soglasnikov. V zgornjem primeru bi torej izpisal besedo „skrbstvo“. Ce je vec besed z enako najvecjo dolžino podniza, je vseeno, katero od njih bo tvoj program izpisal. Obdela naj vse besede do konca standardnega vhoda (eof).