
Mislimo si preprost dokument v jeziku html — poleg besedila vsebuje še oznake oblike <ime> in </ime>, pri čemer je „ime“ ime enega od elementov jezika html. (Jezik html dovoli v oznakah sicer tudi še presledke in atribute, v besedilu pa komentarje, vendar predpostavimo, da v naših dokumentih teh reci ne bo.) Napiši program, ki prebere s standardnega vhoda (ali pa datoteke) nek takšen dokument v jeziku html, in za tisti del dokumenta, ki leži med oznakama <body> in </body>, izpiše vse besedilo (ne pa tudi oznak). Pri izpisu naj tudi skoči v novo vrstico na vsakem takem mestu, kjer se v vhodnem dokumentu pojavi oznaka <br> oziroma <br/> .
Izpis HTML-ja
Izpis HTML-ja
Tjaša Dragar

Navodilo naloge
Opis problema
Mislimo si nek preprost dokument v jeziku html, ki vsebuje nekaj besedila in nekaj značk, pri čemer so začetne značke oblike <ime>, končne značke pa oblike </ime>. Posebna značka je <br> ali <br/> , ki pomeni skok v novo vrsto.
Primer dokumenta v jeziku html:
v tekstovnem dokumentu
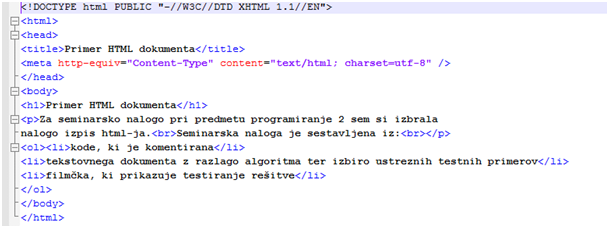
prikaz v brskalniku

Želimo narediti program, ki bo najprej iz celotnega dokumenta dobil le del dokumenta, ki se nahaja med značkama <body> in </body>. Nato bo potrebno najprej vse značke "<br> ali <br/> zamenjati s skokom v novo vrsto, na koncu pa še vse preostale značke zamenjati s praznim nizom. Tako bomo dobili le besedilo brez značk.
Ideja rešitve
Reševanje zgornjega problema sem si zamislila s pomočjo regularnih izrazov. Z njimi je namreč enostavno iskati pojavitve nekih podnizov(vzorcev) znotraj niza. V našem primeru bo celotni niz najprej kar celotno besedilo v jeziku html, nato bomo iz tega poskusili dobiti le besedilo med značkama <body>(napisali bomo vzorec, ki bo ustrezal temu pogoju). V nadaljevanju bomo delali na tako dobljenem besedilu in s pomočjo regularnih izrazov poiskali vse pojavitve značk<br> ter jih zamenjali s skokom v novo vrsto, na koncu pa enako naredili še za ostale značke, le da jih bomo odstranili, to pomeni, da jih bomo zamenjali s praznim nizom.
Razlaga algoritma
Koda programa se nahaja v spodnjih dveh datotekah: Izpis Html Pretvori
Program, ki bo rešil zgornji problem sem si zamislila s pomočjo dveh metod. Ena bo glavna(to je metoda izpis, ki se nahaja v datoteki izpisHTML.py), s pomočjo katere bomo ugotovili na kakšen način bo uporabnik vnesel besedilo v jeziku html(možnosti: preko standardnega vhoda, preko datoteke ali pa preko spletnega naslova) ter na koncu tudi izpisali rezultat. Druga metoda(metoda convert, ki se nahaja v datoteki pretvori.py) pa bo s pomočjo regularnih izrazov dobila ustrezno besedilo. Poglejmo si najprej metodo convert, ki kot parameter sprejme neko besedilo(kako se to besedilo pridobi pa poskrbi glavna metoda izpis). Ker bomo delali z regularnimi izrazi(re) je potrebno uvoziti še ustrezen modul, to je import re. Najprej s pomočjo metode search poiščemo pojavitev vzorca '<body>.*</body>' v celotnem dokumentu. Ta vzorec predstavlja poljubno besedilo, ki lahko vsebuje tudi druge znake(ne le črke), med značkama body. Dobljeni rezultat shranimo v spremenljivko body. Ker nam metoda search ne vrne besedila tipa string ampak objekt, pridobimo besedilo v naslednjem koraku s pomočjo ukaza body.group(0). Vse nadaljne spremembe delamo kar na besedilu(vse shranimo v spremenljivko besedilo) in s tem sproti popravljamo prvotno besedilo, ter na koncu v tej spremenljivki hranimo rezultat, ki ga tudi želimo izpisati. V naslednjem koraku s pomočjo metode sub, ki omogoča menjavanje nekega vzorca v nizu s poljubnim drugim nizom, znački <body> in </body> zamenjamo s praznim nizom. Trenutno imamo v spremenljivki besedilo shranjeno besedilo z vsemi značkami, ki je bilo v originalu zapisano znotraj značk <body>. V naslednjem koraku znački <br> in <br/> s pomočjo metode sub zamenjamo s skokom v novo vrsto, to je \n . V zadnjem koraku pa še vse preostale značke(vzorec za to je : '</?[^<>]*>', kjer znak ^ pomeni vse razen znaka zapisanega za tem) zamenjamo s praznim nizom, to je '' . Tako imamo na koncu v spremenljivki besedilo shranjeno besedilo, ki ustreza pogojem v navodilu. Sedaj pa si poglejmo še metodo izpis, ki je metoda brez parametrov. Najprej od uporabnika zahtevamo, da izbere način vnosa dokumenta v jeziku html, ki ga želi pretvoriti. Uporabnik to lahko naredi na sledeče 3 načine: vnos preko standardnega vhoda(v tem primeru v spremenljivko izbira shranimo vrednost 1), vnos poti do datoteke(v tem primeru v spremenljivko izbira shranimo vrednost 2) in pa vnos spletnega naslova(v tem primeru v spremenljivko izbira shranimo vrednost 3). Če je izbira enaka 1, se uporabniku na zaslon izpiše sporočilo, naj vnese besedilo. Kar uporabnik vnese se shrani v spremenljivko besedilo. Če je izbira enaka 2, se uporabniku izpiše sporočilo, naj vnese pot do datoteke v kateri se nahaja besedilo v jeziku html in to shranimo v spremenljivko imeDatoteke. Uporabnik lahko vnese pot relativno(npr. test.html, če se ta dokument nahaja v istem imeniku kot datoteka izpisHTML.py) ali pa absolutno(npr. H:\Dokumenti\FAX\1. letnik\RP\6.vaja\skoki.html). Najprej preverimo, če datoteka s tem imenom res obstaja, nato pa jo odpremo za branje. S pomočjo metode read preberemo celotno datoteko in rezultat shranimo v spremenljivko besedilo. Če je izbira enaka 3, se uporabniku izpiše sporočilo, da naj vnese spletni naslov. S pomočjo modula urllib odpremo ta spletni naslov in rezultat shranimo v spremenljivko ime. Nato pa s pomočjo metode read ta dokument še preberemo in dobljeni rezultat shranimo v spremenljivko besedilo. Tako imamo torej v vseh primerih v spremenljivki besedilo shranjeno besedilo, ki ga želimo spremeniti. Zato na koncu le še pokličemo metodo convert() in rezultat izpišemo na zaslon(print(pretvori.convert(besedilo)).
Razlaga testnih primerov
Glede na to, da lahko uporabnik besedilo vnese na 3 načine, sem tudi testiranje razdelila na 3 dele.
Izbrala sem naslednje testne primere:
Testiranje 1: v primeru, da od uporabnika zahtevamo vnos besedila v jeziku html.
- test1: uporabnik vnese ustrezen dokument v jeziku html
Rezultat: dobimo ustrezno preoblikovano besedilo(odstranjene značke, skoki v novo vrsto)
- test2: uporabnik vnese neustrezen dokument v jeziku html(npr. ni zaključne značke </body>)
Rezultat: PretvoriError: Besedilo ni mogoče pretvoriti.
- test3: uporabnik ne vnese ničesar
Rezultat: PretvoriError: Besedilo ni mogoče pretvoriti.
Testiranje2: uporabnik vnese pot do datoteke v kateri se nahaja besedilo
- test4: uporabnik vnese relativno pot do datoteke, ki obstaja(npr.test.html)
Rezultat: dobimo ustrezno preoblikovano besedilo
- test5: uporabnik vnese absolutno pot do datoteke, ki obstaja(npr. H:\Dokumenti\FAX\1. letnik\RP\6.vaja\skoki.html)
Rezultat: dobimo ustrezni preoblikovano besedilo
- test 6: uporabnik vnese pot do datoteke, ki ne obstaja
Rezultat: AssertionError: Datoteka s tem imenom ne obstaja.
- test 7: uporabnik vnese pot do datoteke, ki sicer obstaja, vendar je v besedilu napaka(npr. ni zaključne značke </body>-test1.html)
Rezultat: PretvoriError: Besedilo ni mogoče pretvoriti.
Testiranje3:
Glede na to, da sem to tretjo možnost vnosa besedila dodala sama(bolj kot zanimivost), in da ne deluje ravno najbolje(težave so v tem, da so spletne strani napisane daleč od enostavnega html jezika, in zato izpisi ne pridejo lepi; največja težava pa je, da je pogosto znotraj značke <body> zapisano še kaj drugega, in tega moj program ne zna pretvoriti), tudi testiranje ni najbolj strogo.
- test 8: uporabnik vnese napačen spletni naslov(npr.najdi.si)
Rezultat: Besedilo ni mogoče dobiti na tem naslovu, nato pa še PretvoriError: Besedilo ni mogoče pretvoriti.
- test9: uporabnik vnese pravilen spletni naslov(npr. http:/ /ads2.veneti.com/test/reke.html)
Rezultat: besedilo se pretvori
Testiranje je nazorno prikazano tudi v spodnjem filmčku:
