
V tej predstavitvi si bomo ogledali, kako delujejo slovarji, kako jih uporabljamo v programskih jezikih C# in Python, in kako so predstavljeni v računalniku.
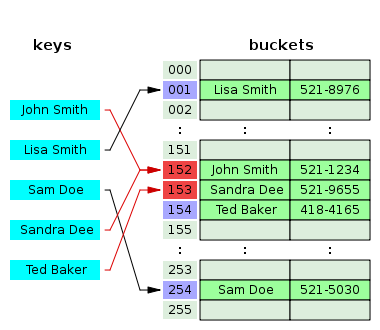
Recimo, da imamo dan telefonski imenik. Kot podatke imamo dane naziv osebe in pa njegovo telefonsko številko. Te podatke moramo sedaj shraniti. Kako bi to storili, da bi do podatkov dostopali enostavno in hitro? Recimo, da si za rešitev tega problema izberemo slovarje. Pa si poglejmo, zakaj bi to v tem primeru bila najboljša rešitev.
Najprej si za lažjo predstavo oglejmo, kaj sploh slovarji so in kje jih uporabljamo.
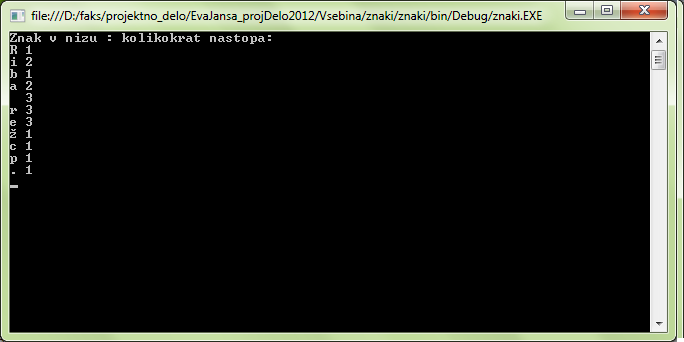
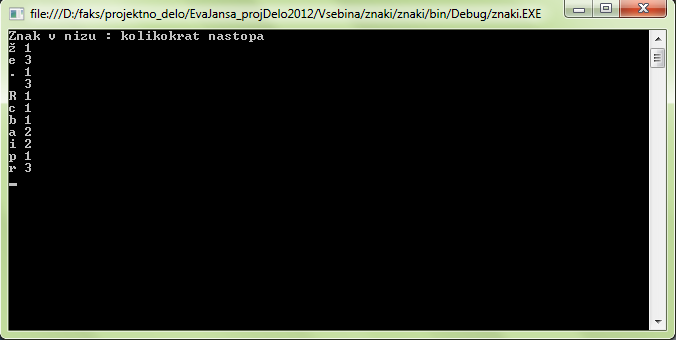
Slovar je abstraktni podatkovni tip. Sestavljen je iz množice parov (ključ, vrednost) tako, da se vsak ključ v množici pojavi samo enkrat.
Osnovne operacije so:
- dodajanje parov (ključ, vrednost) v zbirko,
- odstranjevanje parov iz zbirke,
- sprememba ali zamenjava vrednosti v zbirki,
- iskanje vrednosti glede na ključ.
Kot bomo videli kasneje na konkretnih primerih, so možne tudi dodatne operacije.
Sedaj pa nazaj na naš primer telefonskega imenika. V slovar bi podatke shranili tako, da so ključi imena (skupaj s priimki), vrednosti, ki jim jih pripišemo, pa so njihove telefonske številke. Seveda moramo pri tem upoštevati, da morajo biti ključi enolično določeni in se ne smejo ponavljati, torej ne smemo imeti dveh oseb z istim imenom in priimkom.
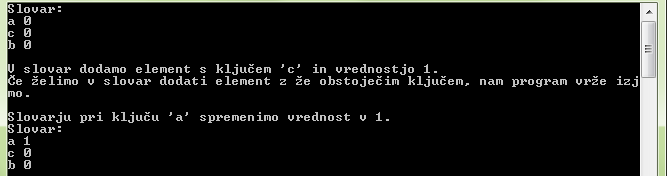
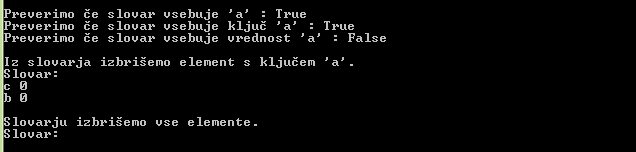
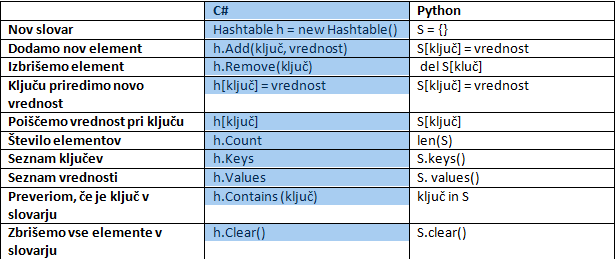
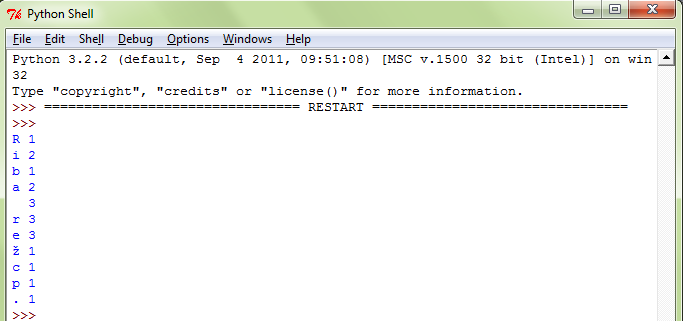
Preden pa si pogledamo nekaj konkretnih problemov, najprej poglejmo, kako v Pythonu in C# izvedemo nekaj osnovnih ukazov nad slovarji.