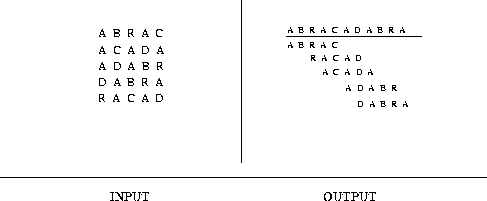
Delamo s tremi seznami, ki hranijo trenutno »aktualne« besede, nize.
En seznam hrani besede, ki smo jih prebrali z datoteke. Drugi hrani tekoče besede, ki se še niso ujemale z drugo besedo ali nizom. Tretji pa hrani nize, ki med besedami ali drugimi najkrajšimi nizi niso imeli ujemanja.
Vzamemo prvo besedo s seznama besed, ki smo jih prebrali z datoteke. Besedo s seznamai zbrišemo, saj je bila že »porabljena«.
Zanka v kateri ponavljamo algoritem, teče vse, dokler je v prvotnem seznamu še kakšna beseda.
Ob vsakem novem koraku v zanki na novo hranimo parametre o tem koliko črk se pri dveh besedah ujema (iščemo takšni dve, pri katerih je to število največje) in pa, kateri sta ti dve besedi. »Porabljeno« besedo moramo izbrisati iz prvotnega seznama, zato hranimo tudi indeks, na katerem mestu v seznamu se ta beseda nahaja.
V zanki je pet korakov. Prvič preverimo ali sta besedi, ujemata v petih znakih, nato ali se morda v štirih, treh, dveh ali v enem. Če najdemo ujemanje, si zapomnimo število znakov, ki se ujemajo in besedo.
Podobno ponovimo pri naslednji primerjavi.
Ko smo preverili vse možne kombinacije besed, vzamemo tisto najboljšo in besedi sklenemo.
Na koncu sklenemo še besede in najkrajše nize, ki se ne ujemajo s preostalimi najkrajšimi nizi.